Data at Rest in RDA Fabric
Robotic Data Automation Fabric (RDAF) provides several types of ways to store metadata and data within the Fabric itself. In most common use cases, RDAF pulls data from various sources or ingests data via streaming and eventually sends to another destination outside the Fabric. In these scenarios, only limited data is saved in RDAF.
| Artifact Type | Description |
|---|---|
| Datasets | Tabular data. Could be input to many pipelines or output from pipelines. |
| Log Archives | Time based storage of data in object storage optimized for long term retention and cost reduction |
| Application Dependency Mappings | Application dependency mappings, typically consumed by AIOps or ITSM applications. Also known as Stacks in RDAF. |
| RDA Objects | Any arbitrary data including binary data such as Images, Videos, Pickled Objects. |
| Job Outputs | Output of recently executed pipelines. |
| Persistent Streams | Automated persistence for any streamed data . |
1. Datasets
In RDA, the term Dataset refers to tabular data and typically stored within RDA fabric.
Supported formats for RDAF datasets are CSV and Parquet.
Storage Location
- Both Dataset Metadata and Data are stored in RDAF Object Storage.
Related Bots
Related RDA Client CLI Commands
dataset-add Add a new dataset to the object store
dataset-delete Delete a dataset from the object store
dataset-get Download a dataset from the object store
dataset-list List datasets from the object store
dataset-meta Download metadata for a dataset from the object store
dataset-query Query dataset from the object store
See RDA CLI Guide for installation instructions
Managing through RDA Portal
- Go to Home Menu -> Click Configuration -> Rda Administration -> Datasets -> Click Datasets
Managing through RDA Studio
- Studio only supports viewing/ exploring of datasets
- In Studio, Select Task: "Explore Datasets"
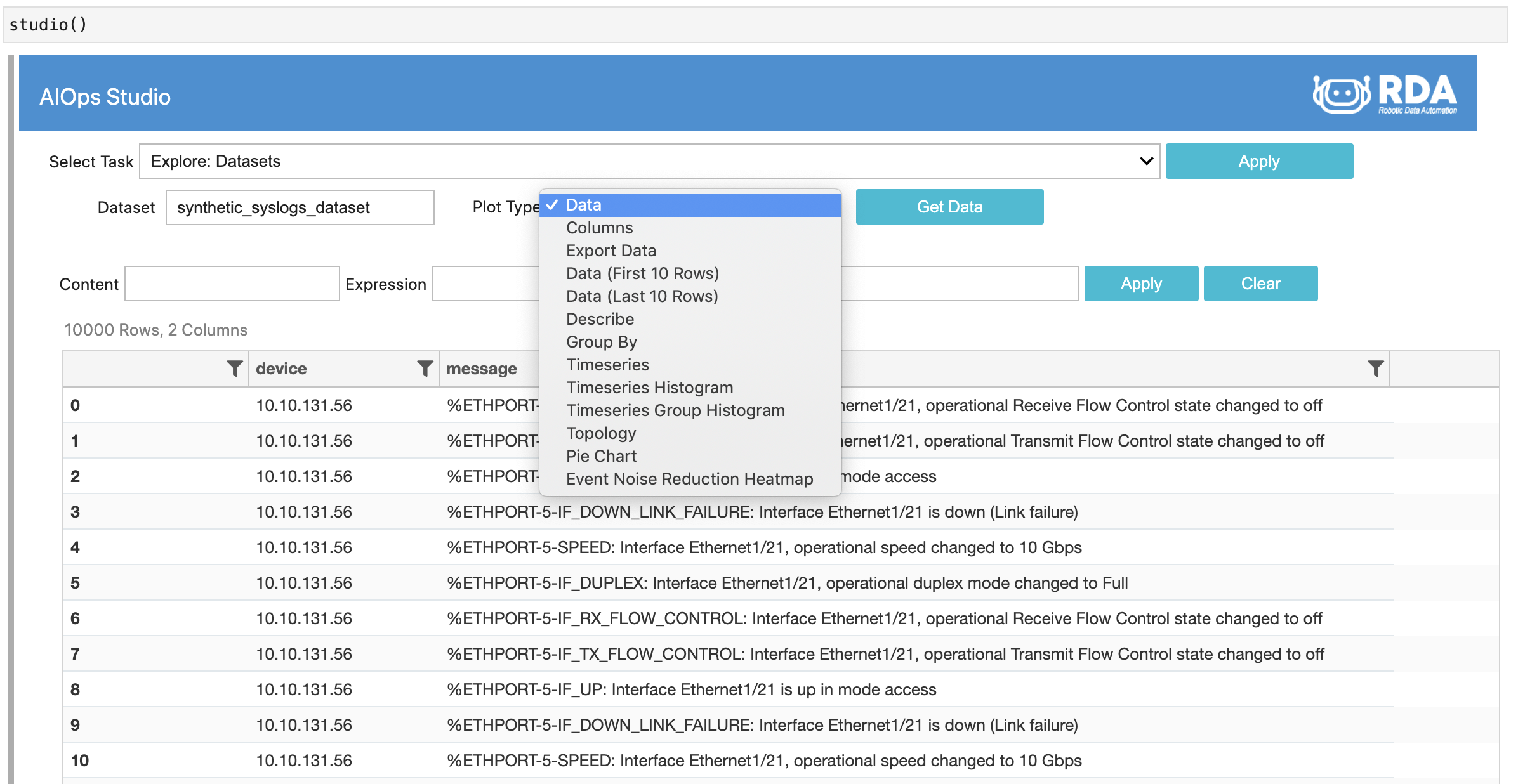
-
Since Studio is a Jupyter notebook, dataset can be accessed using
get_datasetfunction. List of all dataset management functions available in notebook:a.
add_dataset(data_or_file, name): Add a dataset usingdata_or_filewith dataset namenameb.
add_dataframe(df, name): Adds dataframedfas a dataset with namenamec.
get_dataset(name): Download specified dataset and return pandas DataFrame.d.
list_datasets():

Examples
- Example Datasets
- Example Dataset Metadata
2. Bounded Datasets
Bounded Datasets are always bound to a specific data model defined using JSON Schema. Bounded datasets can also be edited in RDA Portal.
This is a new feature introduced in May 2022
Example JSON Schema for Bounded Datasets
Storage Location
- Both Bounded Dataset Data and Schema are stored in RDAF Object Storage.
Managing through RDA Portal
- Go to Home Menu -> Click Configuration -> Rda Administration -> Datasets -> Click Schemas
3. Log Archives
Log Archives are time based storage of data in object storage, optimized for long term retention and cost reduction. Log Archives store streaming log data in S3 like storage. Each Log Archive Repository may contain one or more named archives, each with data stored in a compressed format at minute level granularity.
Log Archives are stored in a user provided object storage in following format:
Object_Prefix/
ARCHIVE_NAME/
YEAR (4 digits)/
MONTH (2 digits)/
DAY (2 digits)/
HOUR (2 digits, 24 hr clock)/
MINUTE (2 digits)/
UUID.gz
Each file under the MINUTE folder is typically a UUID based name to uniquely identify the ingestor or pipeline saving the data. Contents of the file are one line per each row of data, encoded in JSON format. Files are stored in GZIP compressed format.
Example contents of the file look like this:
Storage Location
-
Typically, Log Archives are stored in one or more S3 compatible storages like Minio, AWS S3, Google Cloud Object Storage, Azure Blob.
-
For demonstration and experimentation purposes, RDAF built-in object storage may also be used.
Related Bots
Related RDA Client CLI Commands
logarchive-add-platform Add current platform Minio as logarchive repository
logarchive-data-read Read the data from given archive for a specified time interval
logarchive-data-size Show size of data available for given archive for a specified
time interval
logarchive-download Download the data from given archive for a specified time interval
logarchive-names List archive names in a given repository
logarchive-replay Replay the data from given archive for a specified time
interval with specified label
logarchive-repos List of all log archive repositories
merge-logarchive-files Merge multiple locally downloaded Log Archive (.gz) files
into a single CSV/Parquet file
Managing through RDA Portal
- Go to Home Menu -> Click Configuration -> Rda Integrations -> Log Archives
Managing through RDA Studio
- Studio does not have any user interface for managing Log Archives.
4. Application Dependency Mappings (Stacks)
Application Dependency mappings are typically consumed by AIOps or ITSM applications.
Application Dependency Mappings capture relationships among various application components and infrastructure components. Dependency Mappings are produced by RDA Pipelines with data retrieved from one or more sources.
See Application Dependency Mapping for more details on how to create Stacks using RDA Bots.
Storage Location
- RDA Fabric Object Storage
Related Bots
- @dm:stack-create
- @dm:stack-connected-nodes
- @dm:stack-filter
- @dm:stack-find-impact-distances
- @dm:stack-join
- @dm:stack-list
- @dm:stack-load
- @dm:stack-save
- @dm:stack-search
- @dm:stack-select-nodes
- @dm:stack-unselect-nodes
Related RDA Client CLI Commands
stack-cache-list List cached stack entries from asset-dependency service
stack-impact-distance Find the impact distances in a stack using asset-dependency service,
load search criteria from a JSON file
stack-search Search in a stack using asset-dependency service
stack-search-json Search in a stack using asset-dependency service,
load searchcriteria from a JSON file
See RDA CLI Guide for installation instructions
Managing through RDA Portal
- In RDA Portal, Click on left menu Data
- Click on View Details next to Dependency Mappings
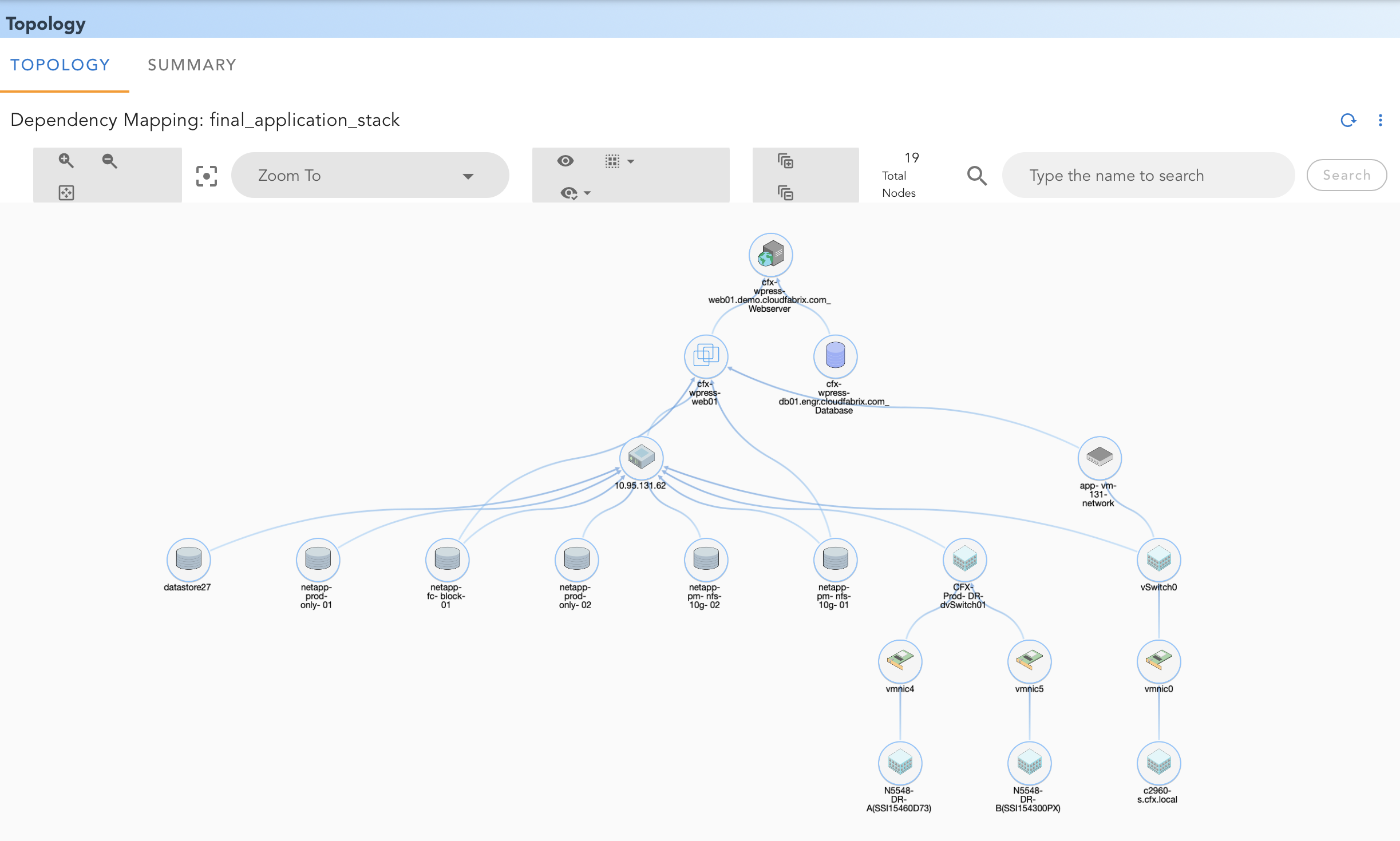
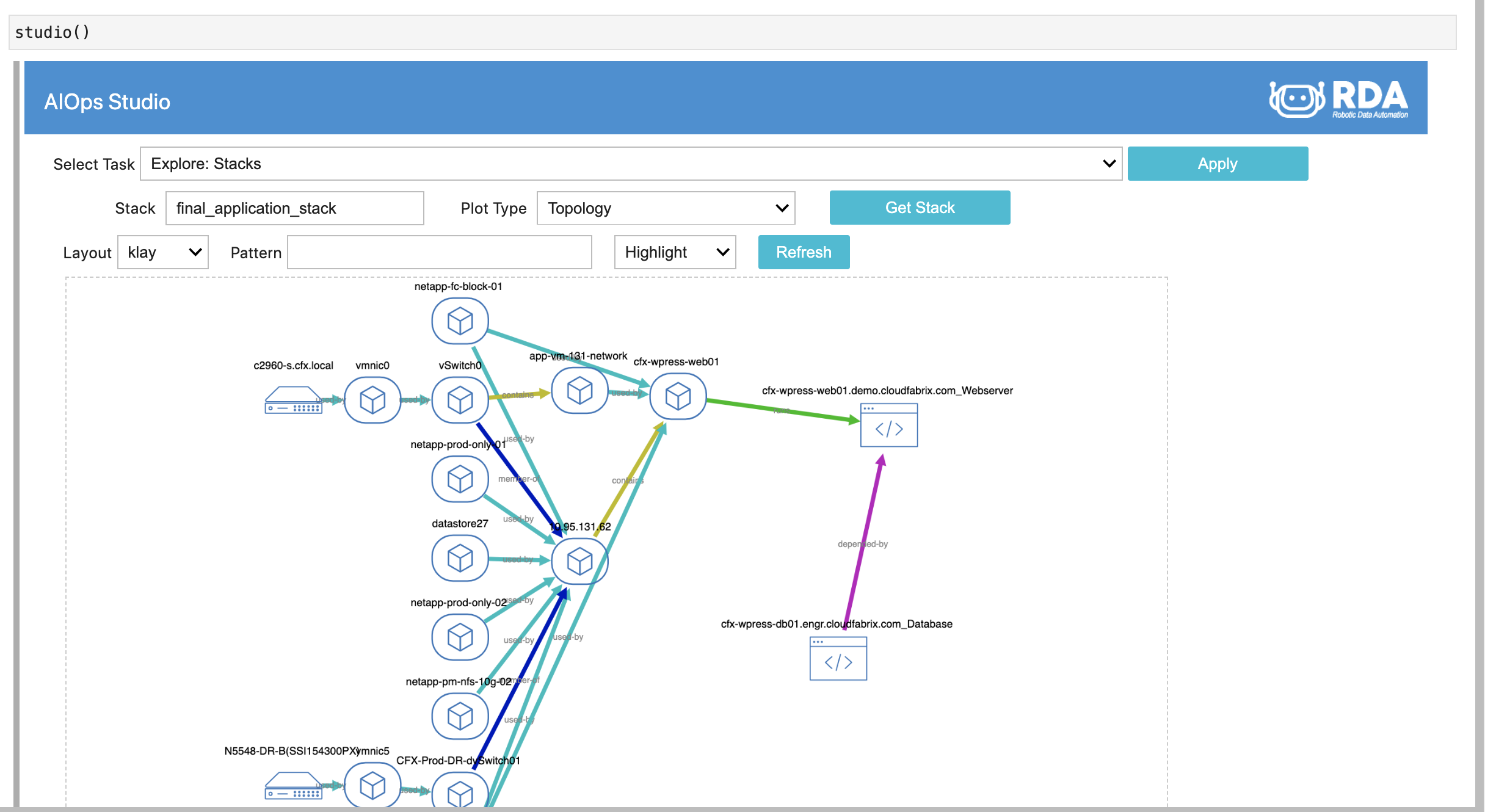
Managing through RDA Studio * Both RDA Studio & RDA Fabric share this artifact * In RDA Studio, Select Task Explore: Stacks
5. RDA Objects
RDA Objects can be any arbitrary data including binary data such as Images, Videos, Pickled Objects.
Storage Location * RDA Fabric Object Storage
Related Bots * @dm:object-add * @dm:object-delete * @dm:object-delete-list * @dm:object-get * @dm:object-list * @dm:object-to-inline-img * @dm:object-to-file * @dm:object-to-content
Related RDA Client CLI Commands
content-to-object Convert data from a column into objects
file-to-object Convert files from a column into objects
object-add Add a new object to the object store
object-delete Delete object from the object store
object-delete-list Delete list of objects
object-get Download a object from the object store
object-list List objects from the object store
object-meta Download metadata for an object from the object store
object-to-content Convert object pointers from a column into content
object-to-file Convert object pointers from a column into file
object-to-inline-img Convert object pointers from a column into inline HTML img tags
See RDA CLI Guide for installation instructions
Managing through RDA Portal
- RDA Objects are only managed by RDA Pipelines & CLI
Managing through RDA Studio * RDA Objects are only managed by RDA Pipelines & CLI
6. Job Outputs
Output of recently executed pipelines. RDAF retains Job Outputs for 4 hours after completion of a pipeline execution job.
If the pipeline developer does not want to save the final output, it is recommended that final bot of the pipeline be @dm:empty
Storage Location * RDA Fabric Object Storage
Related RDA Client CLI Commands
7. Persistent Streams
RDA Streams allow streaming of data from Edge to Cloud and between pipelines. Persistent Streams allow automatic persistence of data into Opensearch (OS) / Elasticsearch (ES).
Persisting continuously streamed data into OS/ES, allows it to be indexed and can be queried.
List of Automatically Persisted Streams
| Stream Name | Retention (Days) |
Description |
|---|---|---|
| rda_system_feature_usage | 31 | RDA Portal and Studio capture all usage metrics by feature. This report is accessible via left side menu Analytics |
| rda_system_deployment_updates | 31 | Audit trail of changes to Service Blueprints |
| rda_system_gw_endpoint_metrics | 31 | RDA Event Gateway data ingestion metrics by ingestion endpoint |
| rda_system_worker_trace_summary | 31 | Pipeline execution statistics by Site, Bots etc. |
| rda_worker_resource_usage | 31 | Resource usage metrics published by RDA Workers |
| rda_system_gw_log_archival_updates | 31 | Log Archive metrics by RDA Event Gateway |
| rda_system_log_replays | 31 | Audit trail of Log Archive replays |
| rda_system_worker_traces | 1 | Detailed execution traces for each pipeline, published by RDA Workers |
Storage Location * Metadata: RDA Fabric Object Storage * Data: In RDA Fabric Opensearch or Customer provided OS/ES (See Data Plane Policy)
Related Bots * @dm:create-persistent-stream
Related RDA Client CLI Commands
pstream-add Add a new Persistent stream
pstream-delete Delete a persistent stream
pstream-get Get information about a persistent stream
pstream-list List persistent streams
pstream-query Query persistent stream data via collector
pstream-tail Query a persistent stream and continue to query for incremental data every few seconds
Deleting Persistent Streams
Deleting a persistent stream only deletes metadata about persistent stream. It will stop persisting any new data.
Does not delete already persisted data from underlying OS/ES.
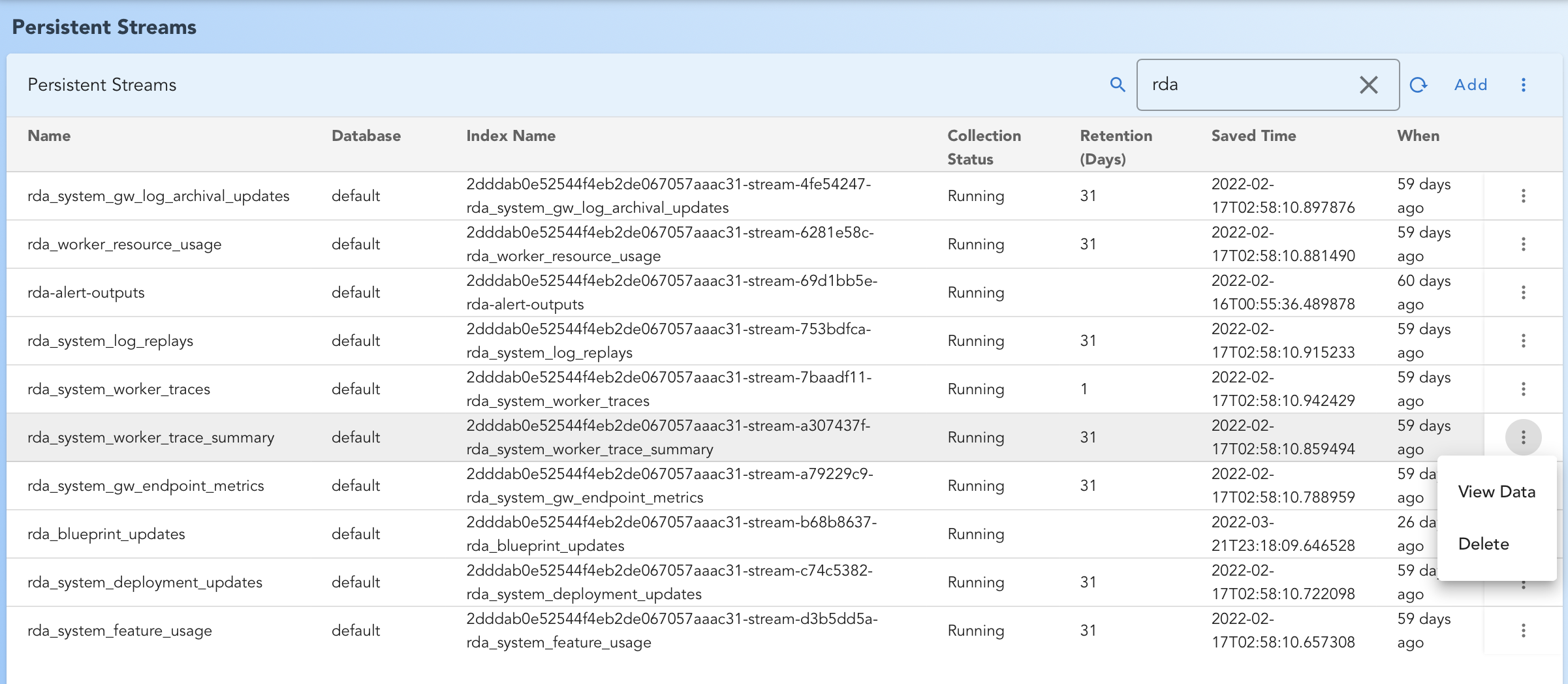
Managing through RDA Portal
In RDA Portal, Click on left menu Data
- In RDA Portal, Click on left menu Data
- Click on 'View Details' next to Persistent Streams
Configuring Data Plane Policy
RDA Fabric available at cfxCloud provides a built-in Opensearch for storing usage data and many operational metrics for RDA Fabric itself.
It can also be used to store data ingested by the Fabric on an experimental basis. To route & store large amount of data, users may provide their own Cloud Hosted Opensearch/ Elasticsearch.
Following is an example how the policy can be configured either for cfxCloud or on-premises or customer's own cloud deployments: