RDA Fabric Architecture
Robotic Data Automation Fabric designed to manage data in a multi-cloud and multi-site environments at scale. One of the primary design principles of RDAF is to perform data operations close to data source. It provides flexibility in choosing the right data operations model based on use case.
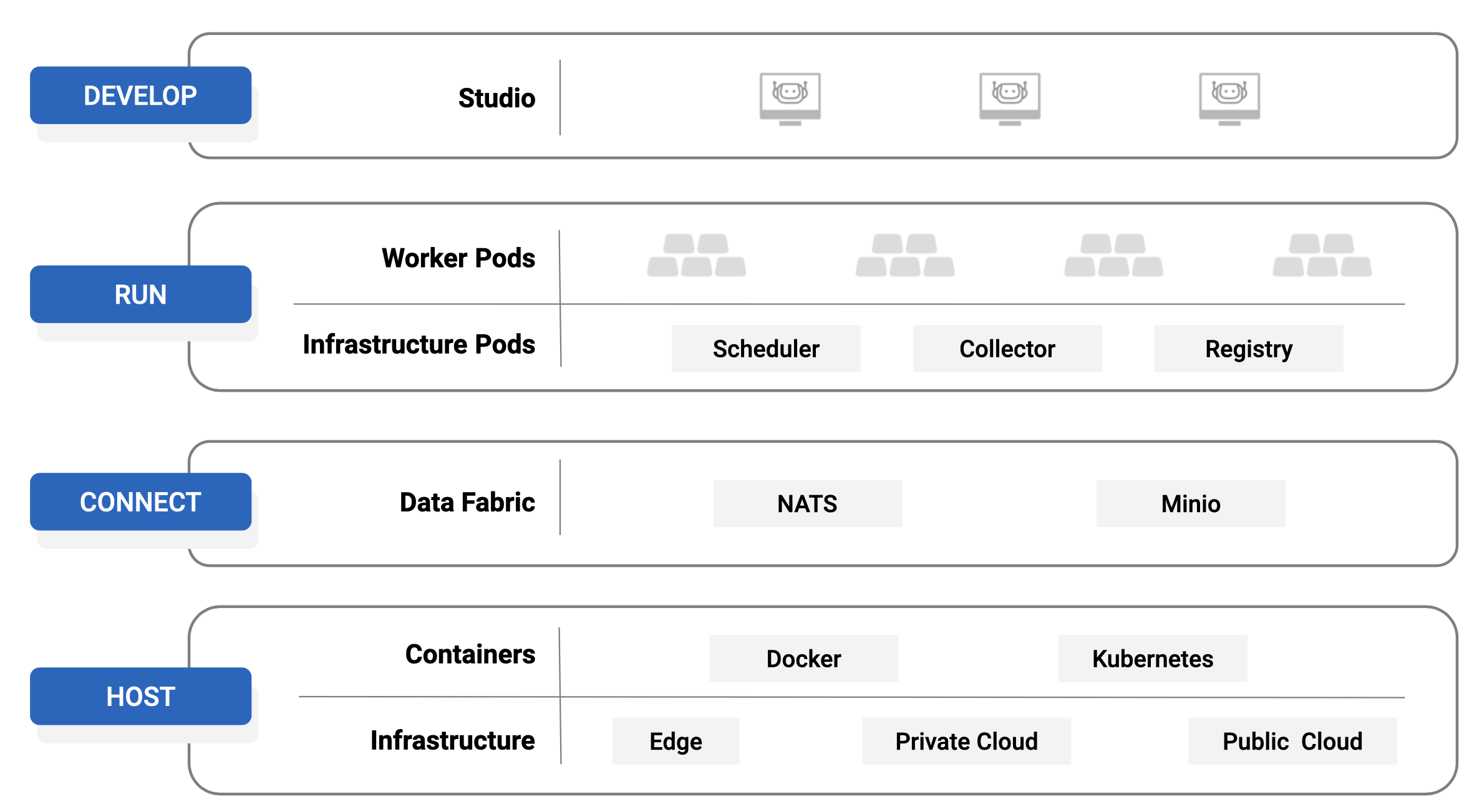
RDAF can be started of as docker container(s) and can be scaled up to a multi-cloud or multi-site deployment.
1. Deployment Models
1.1 Comparison of Deployment Models
| Deployment Model | Starter | Standard (cfxCloud) | Distributed |
|---|---|---|---|
| Microservices | |||
| RDA Studio | |||
| registry | |||
| worker | |||
| scheduler | |||
| collector | |||
| api-server | |||
| Data Infrastructure | |||
| NATS | |||
| Minio | |||
| MariaDB | |||
| Opensearch | |||
| Features | |||
| Pipeline Development | |||
| Pipeline Publishing | |||
| ML Bots | |||
| Streams Support | |||
| Persistent Streams | |||
| Event Gateway based Ingestion | |||
| Staging Area based Ingestion | |||
| Service Blueprints | |||
| Multi-Site Workers |
1.2 Deployment Model: Starter
This deployment is suitable to get started with RDA Fabric.
- Intended for pipeline development and validation.
- Can be deployed on laptops or desktops
- Should not be used for production
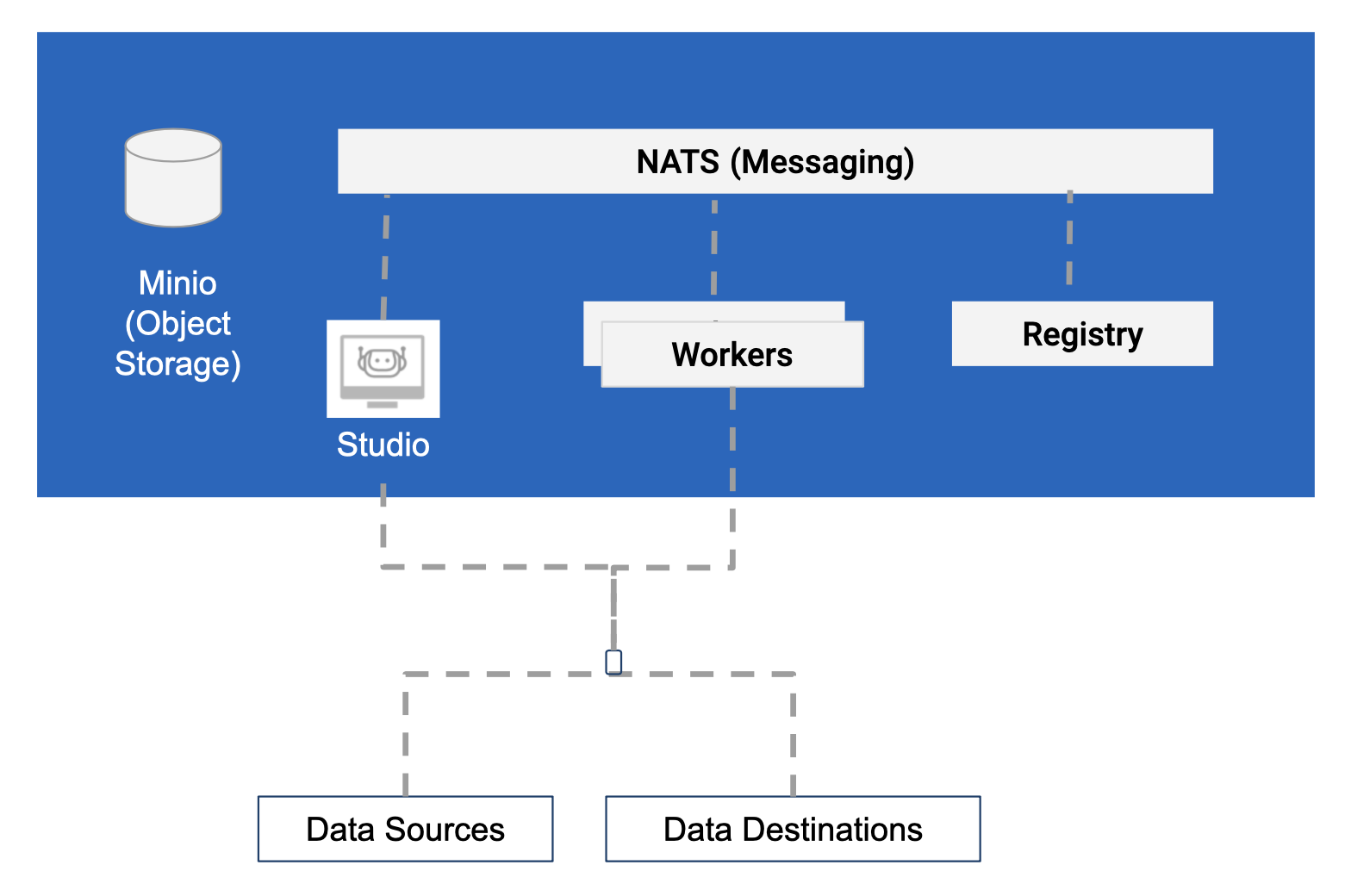
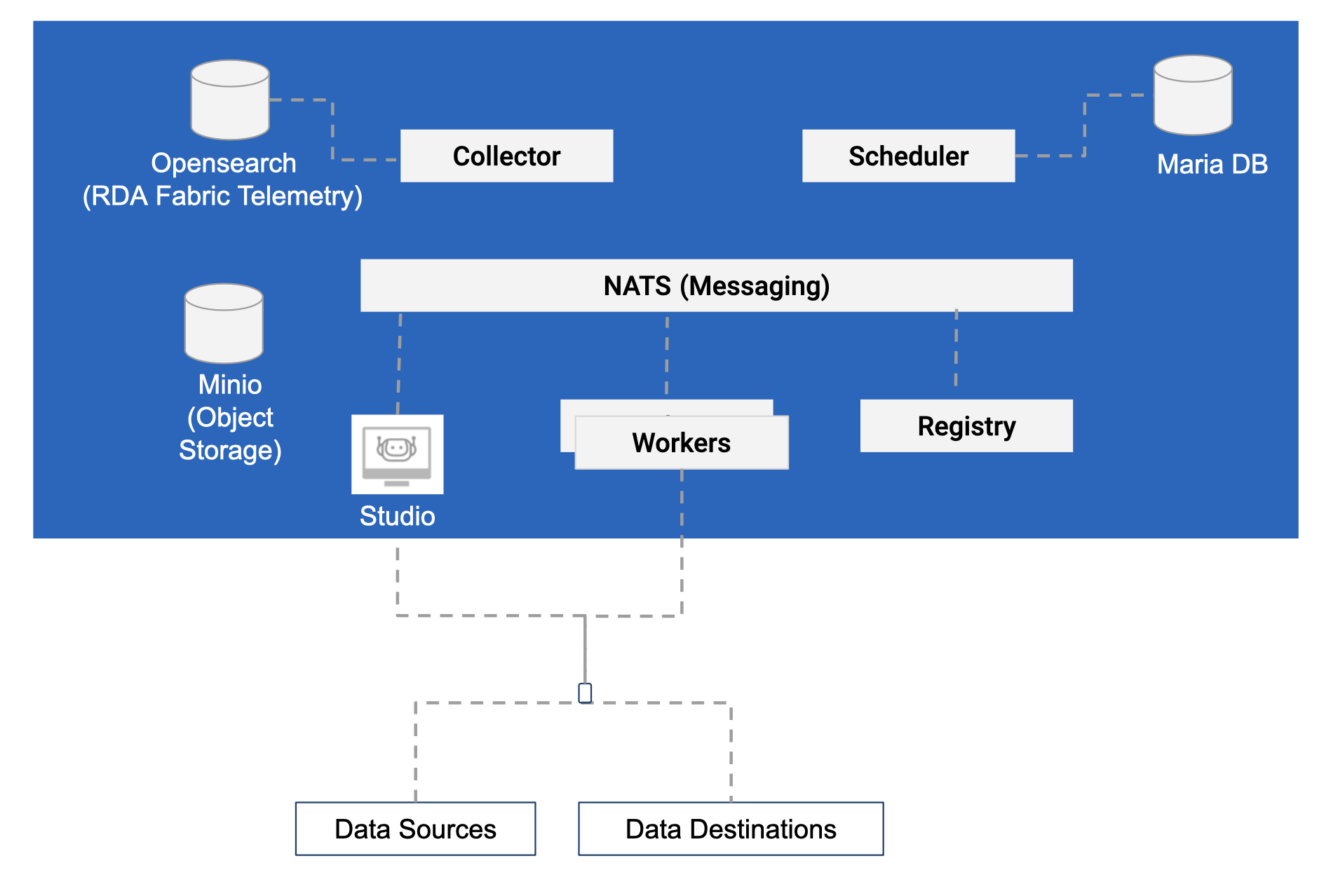
1.3 Deployment Model: Standard
This deployment is suitable for many production deployments:
- Intended for pipeline development and validation.
- Should be deployed on Private Cloud or Public Cloud
- Managed Kubernetes environments are recommended but docker can also be used.
- cfxCloud uses this model for all tenants
1.4 Deployment Model: Distributed
Distributed deployment is used when data needs to be processed closer to data sources or edge locations.
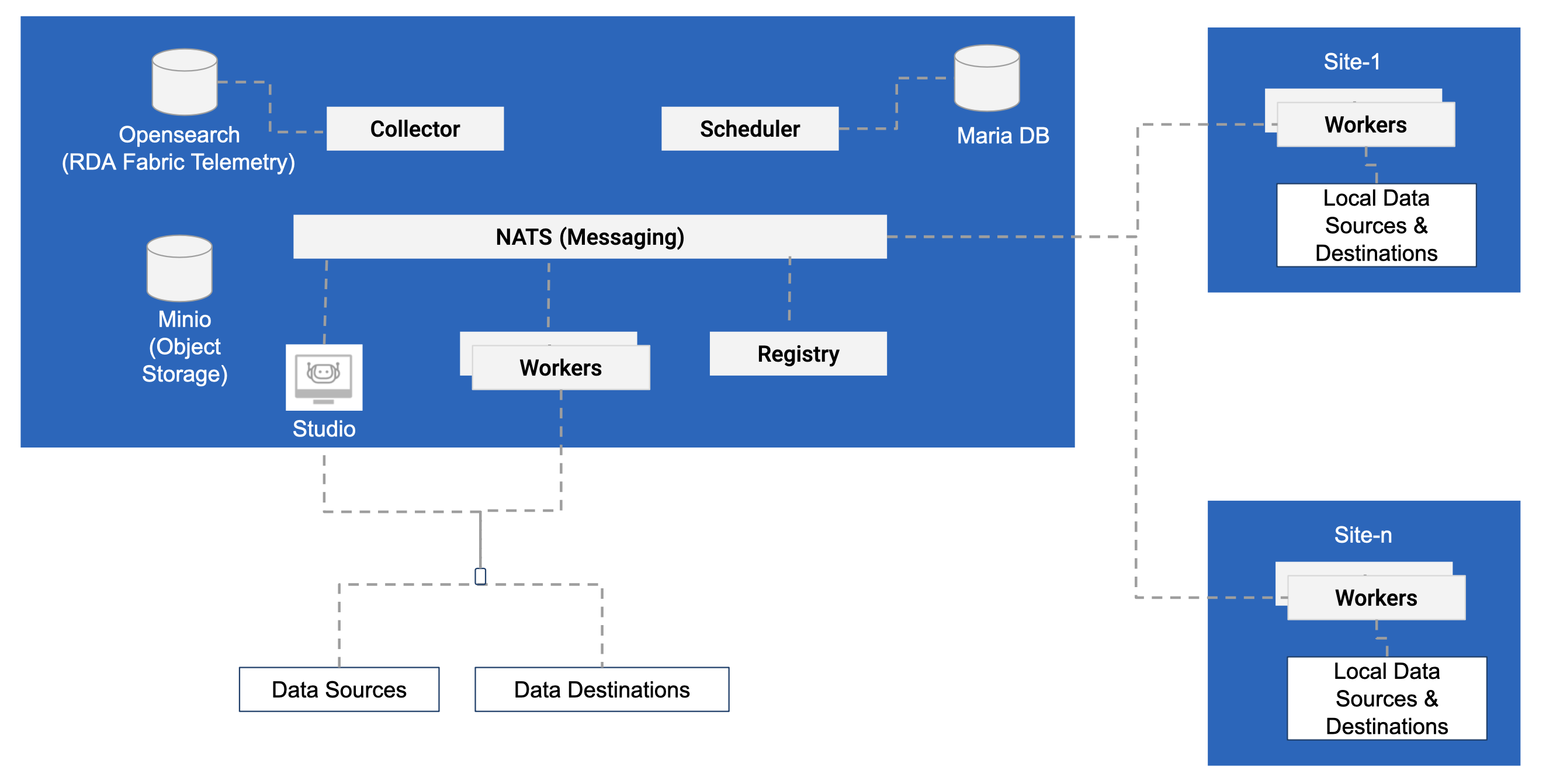
RDA provides event gateway which can be used to ingest many types of streaming data into RDA Fabric.
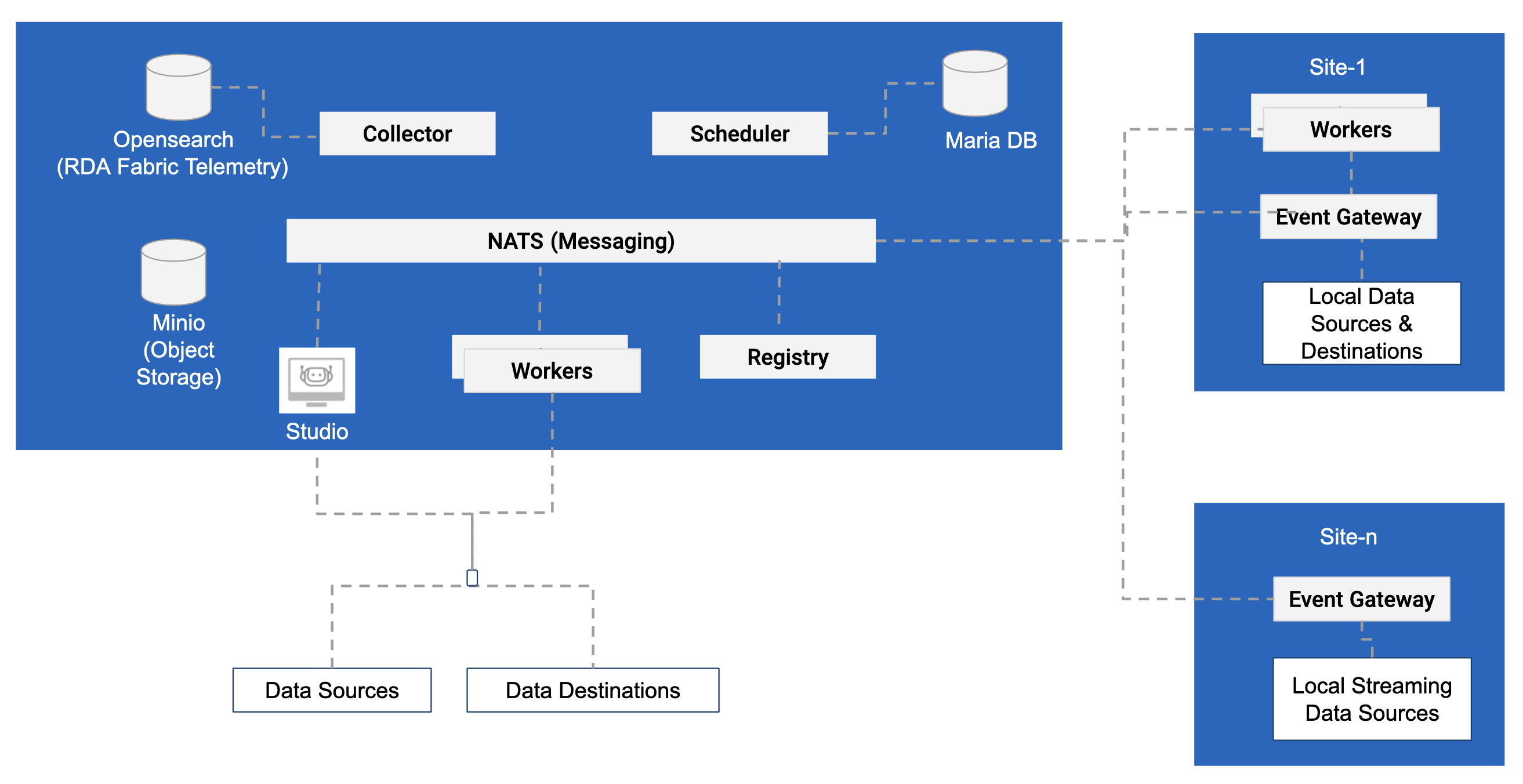
2. Fabric Components
This section provides details on various RDA Fabric components.
2.1 RDA Studio
RDA Studio is a Jupyter notebook based environment to develop and test RDA Pipelines. Jupyter notebook can be deployed anywhere as long as it can access NATS and Minio from it's location.
RDA Studio is optional component for production environments.
2.2 Worker
RDA Worker is a microservice which is essential to the functioning of RDA Fabric. RDA Worker runs all pipelines (except when Pipelines are run in Studio). RDA Worker capacity is measured by number of cores available and amount of Memory (GB) available.
Any number of workers can be deployed to achieve greater scale. Each worker must specify a site name. Any given site may contain one or more workers in it.
2.3 Registry
RDA registry manages a dynamic registry of all RDA Microservices. For High Availability (HA), at least two instances of Registry should be deployed on two different nodes.
2.4 Scheduler
RDA Scheduler is a microservice scheduler that manages life cycle and state of all schedules within RDA Fabric.
This service requires access to Maria DB (MySQL) to manage life cycle and state of all schedules.
Scheduler also manages Staging Area based ingestion and Service Blueprints.
For HA, at least two instances of Scheduler services should be deployed. scheduler microservice uses leader election protocol to select a primary instance.
2.5 Collector
RDA Collector manages RDA Fabric telemetry and all Persistent Streams. RDA Collector requires access to one ore more Opensearch (Elasticsearch) instances.
RDA Fabric Telemetry includes:
- Traces for all pipelines executed by any worker at any site
- Resource usage data for all workers
- Ingestion data metrics for Event Gateway and Staging Area
- Log Archiving data metrics for all workers
- Any additional metrics and audit logs produced by various Service Blueprints
For HA, at least two instances of Collector services should be deployed. All instances of collector services will be in Active-Active mode.
2.6 API Server
RDA API Server acts as a gateway between User Interface and all NATS based microservices. It provides HTTPS & REST like APIs for any client that need to interact with RDA Fabric.
2.7 Event Gateway
RDA Event Gateway allows ingestion of streaming data from an edge or datacenter into RDA Fabric.
Event Gateway can ingest following types of events from local devices or event aggregators such as fluentd, fluentbit, rsyslog and filebeat
Some of the supported ingestion types are:
- Syslog UDP
- Syslog TCP (with or without SSL)
- TCP JSON (with or without SSL)
- HTTP(S)
- Filebeat (supports both filebeat and winlogbeat log shipping agents)
- SNMP Traps
Event Gateway can also be configured to directly archive any ingested data into cheaper object storage such as AWS S3 or Minio or any compatible object storages.