Guide to AI & Machine Learning in RDA Fabric
This guide has following sections:
- Natural Language Processing (NLP) in RDA
- Unsupervised Clustering in RDA
- Timeseries Data Regression in RDA
- Classification in RDA
1. Natural Language Processing (NLP) in RDA
Here are some of the common NLP techniques available and how each might be useful in AIOps or Autonomous Enterprise use cases.
| Technique | Description |
|---|---|
| Sentiment Analysis | Review of human generated text such emails, reviews, comments, human opened tickets, for sentiment. Sentiment can be positive or negative or neutral. Complex messages may contain multiple polarities in the same text. Understanding sentiment can help route the reviews & tickets to different teams and prioritize certain feedback. |
| Named Entity Recognition | Also known as NER, can detect certain named entities such as Organization names, geographical information etc. Certain NLP processors can also take custom NER dictionary to identify non-public information. Identifying named entities will help route tickets, reviews, feedback to right group in automated fashion. |
| Keyword Extraction | Keyword Extraction is the automated process of extracting the most relevant information from text using AI and ML algorithms. This will help the text to be more searchable, helps with automated linking of knowledgebase to issues. |
| Summarization | It is a technique to make a complex text of sentences into its most basic terms using natural language processing in order to make it more understandable. |
1.1 NLP using RDA Built-in ML Bots
RDA's Built in NLP Extension provides several bots. We will use some of them, to help us understand these bots.
Let us start with a simple text. We will make up scenario where a human is describing a critical issue in an IT environment:
Issue with my virtual machines: I have two virtual machines for my app and One virtual machine has been patched yesterday and it worked fine.
After attempting update the second virtual machine with same patch, now both VMs are intermittently shutting down.
This is a serious issue affecting European and Australian customers and impact could be $10M per day
Let us use @dm:empty and @dm:addrow to initialize a single row dataset:
Let use @nlp:analyze-sentiment to analyze sentiment in that text. Now the updated pipeline looks like this
Playground
Let us take a look at RDA Studio Output:
| Column | Value |
|---|---|
| neg_polarity | -0.111 |
| neg_subjectivity | 0.222 |
| neg_sentence | This is a serious issue affecting European and Australian customers and impact could be $10M per day |
| pos_polarity | 0.417 |
| pos_subjectivity | 0.5 |
| pos_sentence | Issue with my virtual machines: I have two virtual machines for my app and One virtual machine has been patched yesterday and it worked fine. |
The sentiment analysis bot added following columns:
neg_polarity: Negative polarityneg_subsctivity: Negative Subjectivityneg_sentence: Most negative sentence in the textpos_polarity: Positive polaritypos_subsctivity: Positive Subjectivitypos_sentence: Most Positive sentence in the textpolarity can range from -1 to 1. -1 being very negative, 0 being neutral and 1 being very positive. Subjectivity can be between 0 and 1. 1 being very subjective (or an opinion, not necessarily factual). Both polarity and subjectivity are relative numbers.
Let us analyze our results.
- It correctly identified most negative sentiment
- It somewhat incorrectly identifies the positive sentiment. But considering higher subjectivity it can be discarded.
There is other important information but that is not the job of Sentiment Analysis. Let us use keyword extraction next:
Playground
Output:
Column Value neg_polarity -0.111 neg_subjectivity 0.222 neg_sentence This is a serious issue affecting European and Australian customers and impact could be $10M per day pos_polarity 0.417 pos_subjectivity 0.5 pos_sentence Issue with my virtual machines: I have two virtual machines for my app and One virtual machine has been
patched yesterday and it worked fine.keywords serious issue affecting european,10m per day,second virtual machine,one virtual machine,two virtual machines,virtual
machines,worked fine,patched yesterday,intermittently shutting,impact couldIt added one more column
keywords. This bot has identified seemingly very important 25 words, in the order of importance to the sentence. Original text had 59 words. These keywords should help prioritize the issue quickly and in automated manner.
Let us add named entity recognition to this pipeline:
Playground
Column Value neg_polarity -0.111 neg_subjectivity 0.222 neg_sentence This is a serious issue affecting European and Australian customers and impact could be $10M per day pos_polarity 0.417 pos_subjectivity 0.5 pos_sentence Issue with my virtual machines: I have two virtual machines for my app and One virtual machine has been patched yesterday
and it worked fine.keywords serious issue affecting european,10m per day,second virtual machine,one virtual machine,two virtual machines,virtual machines,worked
fine,patched yesterday,intermittently shutting,impact couldnamed_entities CARDINAL (Cardinal): two,One DATE (Date): yesterday ORDINAL (Ordinal): second NORP (Nationalities or Regions): European,Australian
MONEY (Money): $10MWe can see this new bot added new column,
named_entities. It has good information about Geographical and Money. But it combined all into single text field. Let us tell the bot to provide important information more consumable way:
Playground
Output
Column Value neg_polarity -0.111 neg_subjectivity 0.222 neg_sentence This is a serious issue affecting European and Australian customers and impact could be $10M per day pos_polarity 0.417 pos_subjectivity 0.5 pos_sentence Issue with my virtual machines: I have two virtual machines for my app and One virtual machine has been
patched yesterday and it worked fine.keywords serious issue affecting european,10m per day,second virtual machine,one virtual machine,two virtual machines,virtual
machines,worked fine,patched yesterday,intermittently shutting,impact couldnamed_entities CARDINAL (Cardinal): two,One DATE (Date): yesterday ORDINAL (Ordinal): second NORP (Nationalities or
Regions): European,Australian MONEY (Money): $10Mner_norp European,Australian ner_date yesterday ner_money $10M Now we have 3 more columns
ner_norp,ner_money,ner_date, which captures specific geographical regions, monetary values and date related information.NOTE: Named Entity Recognition bot @nlp:extract-named-entities also accepts
custom_named_entities_dictparameter. You can provide a pre-created dataset with custom NER labels and patterns to improve the recognition for non-public entities (such as your business unit / organization names, product names, application names).
1.2 NLP using IBM Watson Bots in RDA
Watson Natural Language Understanding is a commercial service that IBM offers which uses deep learning to analyze text to extract meaning and metadata from content such as concepts, entities, keywords, categories, sentiment, emotion, relations, semantic roles, and syntax etc. This is easily accessible using IBM Watson RDA Bots
Lets take a look at the some of the bots RDA Watson extension provides
| Bot | Description |
|---|---|
| @watson:categories | Get a hierarchical taxonomy of the content/text. For example, a news website may return categories like /international news or /arts or /entertainment. |
| @watson:concepts | Gets high-level concepts in the content. For example, a research paper about deep learning might return the concept, "Artificial Intelligence" although the term is not mentioned. |
| @watson:keywords | Gets important keywords in the content. For example, analyzing a company's press release could return keywords such as "sustainability", "aiops", or "RDAF". |
| @watson:sentiment | Analyzes the general sentiment of your content or the sentiment toward specific target phrases. As an example, the phrase "Thank you it was a pleasure meeting you!" returns a positive sentiment. |
| @watson:run-nlp | This is used to run all the watson bots together instead of each bot alone. For example if we want to return categories, keywords and sentiment at once we can mention it in parameter features = "categories,keywords,sentiment" |
IBM Watson Bots does not require any training data or trained model. It works on pre-trained models built using advanced deep learning techniques. So all the results are generated instantaneously based on the input data.
Let us understand more about this extension with an example pipeline.
Here is the output of the above pipeline:
| description | categories | concepts | keywords | sentiment |
|---|---|---|---|---|
| Storage disk went into a read-only mode and unable to write. ERP app backup tasks are failing. Reboot did not help | /technology and computing/enterprise technology/enterprise resource planning | USB flash drive, Computer data storage | Storage disk, ERP app backup tasks, Reboot | negative |
| I was not able to login into my desktop. After reboot, I am now able to login. It is all working now. Thank you for the help | /technology and computing/operating systems, /technology and computing/hardware/computer/servers, /technology and computing/operating systems | The Help | reboot, login, desktop | positive |
| IT Device: Rack2-Switch-2.cfx.local, Device IP: 10.95.158.251, Interface 'GigabitEthernet0/12' is down | /technology and computing/hardware/computer networking/router, /technology and computing/operating systems, /technology and computing/hardware/computer peripherals | IT Device, Device IP, Interface 'GigabitEthernet0 | neutral |
1.3 NLP using OpenAI Bots in RDA
OpenAI offers a commercial service which hosts a set of pre-trained natural language models which can be accessed using RDA OpenAI Bots. If you do not have an account with OpenAI, see the page and see instructions for SIGNUP.
Most common use cases for OpenAI in RDA are:
- Text classification: RDA provides @openai:classify bot to classify a given text using OpenAI's Semantic Search.
- Text completion: RDA provides @openai:complete bot to complete a given text using one of the pre-trained models.
OpenAI offers many different use cases for leveraging GPT-3 models. @openai:complete bot can be used for most the of these use cases.
Let us see how we can use OpenAI in AIOPs use case. Whenever a new ticket is created in an ITSM system, we want to read the description to identify the department (assignment group) to handle the ticket. First we create a dataset to use some keywords to describe what types of tickets each group handles:
Let us simulate two incidents INC001 and INC002 with brief descriptions. The complete test pipeline looks like this
In this example we are using davinci model of GPT-3, which is the most powerful engine but expensive (per token cost). Other available engines at OpenAI are ada, babbage and curie.
Let us see the output of the above pipeline:
description incident_id assignment_group unable to write to disk INC001 Storage Group Hyper-V host rebooted INC002 Virtualization Group
2. Unsupervised Clustering in RDA
Unsupervised learning is machine learning technique in which the model learns patterns from unstructured/untagged data without the need of users to supervise or label the data.
RDA Fabric utilizes this technique in grouping raw data into meaningful clusters with its Clustering Extension.
Once Raw data is clustered it also provides a trained classifier with generated clusters as its labels, which allows users to leverage live predictions in real time at scale (i.e It does Clustering and also serves it as Classification model for predictions in single training run).
Here are the list of bots RDA Clustering extension provides
| Bot | Description |
|---|---|
| @cfxusml:logclustering | Cluster any textual data like logs, alerts messages, incident descriptions,Summaries, comments etc. |
| @cfxusml:logpredict | Along with generating meaningful clusters it provides a trained classifier model for prediction determining which cluster new data point maps to. |
Let us take a typical AIOPS example use case where we have raw alerts data and want to group all similar alerts together to derive an actionable insight. Instead of looking at all alerts we can group each issue into one cluster and ignore the noise.
Here is how the sample data looks like:
| id | message |
|---|---|
| da147628-dc05-42ed-8b32-128632f9edcc | CPU utilization [100.0%] exceeded configured value 95.0% |
| c7f01447-056e-4100-aab9-e2d954423519 | Default alarm to monitor virtual machine CPU usage |
| e914029a-310d-491e-8ec1-6e2fef6c9afc | Device is unreachable via ICMP |
| 954c31c5-b7af-4891-8c07-9bed0d5a50b9 | Device is unreachable via SNMP |
Let us load this file using @files:loadfile bot and use @cfxusml:logclustering bot to perform Clustering. Here is how simple the clustering pipeline looks like
Playground
Now letus understand more on what is happening inside the bot
-
The bot takes inputs such as
column_name: what columns to cluster from input dataframemodel_name: Name of the model for the trained data. Will be used in predictions.min_cluster_size: Minimum cluster size. Which typically means how many minimum data points needed for the algorithm to consider it as one cluster. ex: if cluster size is 50 i.e each cluster will have a minimum of 50 similar data points, if there are any similar points less than themin_cluster_sizethey will be merged into nearest possible cluster and if any data which is not similar to any cluster they are tagged as Anomalies.
-
Next, it takes all the data does pre_processing of data like : Stemming, Stop words removal, Lemmatisation, De-variabilization etc using its built-in NLP techniques.
- Upon cleaning the text each data point(row) is then projected into high dimensional vectors using techniques like Tf-Idf, Word2Vec, Singular Value decomposition(SVD) etc.
- Then the vectorised data is fed into to its core Unsupervised Algorithm which extends DBSCAN by converting it into a Hierarchical clustering model
- Each row in the dataset is updated with a Cluster label staring with (Cluster-0 to Cluster-N), any data that doesn't have similarities will be tagged as Anomalies.
Let us take a look at RDA Studio output of one of the rows after Clustering.
| Column | Value |
|---|---|
| id | 14752b17-844d-408b-a760-f14da0c29a49 |
| message | Average (1 samples) total cpu is now 100.00%, which is above the error threshold (95%).Top Processes |
| pre_processed_data | average samples total cpu error threshold top processes |
| cluster | Cluster-5 |
| probability | 0.98 |
The clustering bot added following columns:
cluster: Name of the cluster group the data belongs to
(starts from Cluster-0 to cluster-n.
Anomalies if the data is not close to any cluster)probability: Probability score for each row to which cluster it belongspre_processed_data: Shows how data looks after pre_processing/cleaning
Here is the sample output of how similar messages each cluster has.
| id | message | pre_processed_data | cluster | probability |
|---|---|---|---|---|
| 1447d4a1-12d3-4e28-a759-9f2c03346554 | Average (5 samples) swap memory usage is now 97.22%, which is above the error threshold (95%) | average samples swap memory usage error threshold | Cluster-5 | 1 |
| 5b9ca4a4-2fe2-4e17-a0a6-45080c9987d3 | Average (5 samples) swap memory usage is now 96.05%, which is above the error threshold (95%) | average samples swap memory usage error threshold | Cluster-5 | 1 |
| 9d02ea70-7b8d-479c-9115-09e1c1d72920 | Average (5 samples) swap memory usage is now 99.22%, which is above the error threshold (9%) | average samples swap memory usage error threshold | Cluster-5 | 1 |
| 9d582be-6a7f-4108-b81f-77705e19df05 | Average (4 samples) disk free on C: is now 5%, which is below the error threshold (5%) out of total size 39.7 GB | average samples disk free error threshold total size gb | Cluster-5 | 0.78 |
| id | message | pre_processed_data | cluster | probability |
|---|---|---|---|---|
| 263799dc-7820-418a-9e4b-5c856dd455ee | Device is unreachable via ICMP | device unreachable via icmp | Cluster-7 | 1 |
| 780cae2d-66e4-4589-949c-94c8a139af7f | Device is unreachable via ICMP | device unreachable via icmp | Cluster-7 | 1 |
| 3012e29f-5ca4-4613-994a-b1b800f403e4 | Device is unreachable via ICMP | device unreachable via icmp | Cluster-7 | 1 |
| 28eaedf7-7ea1-41d3-a5ed-7f63398e595c | Device is unreachable via ICMP | device unreachable via icmp | Cluster-7 | 1 |
Along with clustered results it also provides a trained Classification model with assigned clusters as its labels, which can then be used for live predictions in real time
To demonstrate this let us load a sample dataset which is not part of the training data and pass the data to @cfxusml:logpredict for prediction. The bot takes model_name as input which is given during training and then predicts to which cluster each row belongs along with the score.
Here is how the pipeline looks like
Playground
Here is the sample output of new alerts.
| id | message | cluster | probability |
|---|---|---|---|
| 5cad0158-a118-4bd2-badf-109714941c43 | Average (3 samples) total cpu is now 97.18%, which is above the error threshold (95%) | Cluster-5 | 1 |
To summarize, we took raw alerts and grouped them into meaningful clusters and also simultaneously trained a classification model to predict which cluster a new alert belongs.
With this we correlated similar alerts together by reducing the noise and serving the model for real time predictions.
Info
Cluster labels generated depends on random initialization of algorithm during training. Label names (Cluster-0, Cluster-1) may vary from each run but accuracy remains same.
3. Timeseries Regression in RDA
Timeseries Data Regression is a Supervised Statistical Machine Learning technique for predicting future events based on historical time series data.
Some of the following are the use cases that can be implemented by leveraging this ML method:
| Technique | Description |
|---|---|
| Time series forecasting | It is a technique for the prediction of events through a sequence of time. It predicts future events by analyzing the trends of the past, on the assumption that future trends will hold similar to historical trends. and using them to make observations and drive future strategic decision-making. |
| Anomaly detection | It is a technique to detect any outliers/anomalies in the time series, these are observations that don’t follow the expected behavior which can lead to any unwanted event. |
RDA Fabric's Regression bot @cfxml:regression provides both Time series forecasting and Anomaly detection at once in a single model
We will use this bot to help us understand more about the above techniques and the bot.
Let us start with a simple time series data where we want to analyze the Memory Usage of a host by detecting anomalies in the data and forecasting the usage pattern into future.
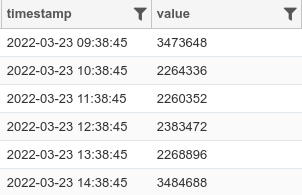
Here value column contains the Memory Usage in bytes.
Let us load this file using @files:loadfile bot and use @cfxml:regression bot to perform both forecasting and anomaly detection of time series. The pipeline will look like this
Playground
Here is how the bot does it's process.
It first pre-processes the data and observes for seasonality spikes, if found it removes them and normalizes the data.
Then bot learns based on an additive model where non-linear trends are fit with yearly, weekly, and daily seasonality.
@cfxml:regression automatically handles the missing data and is robust to shifts in the trend, and typically handles outliers well.
Upon training the bot will generate next seven days of forecast by default (which is configurable and can be configured using prediction_duration parameter in the bot) and will append to the historical data.
Any anomalies detected will be in the anomalies column.
Output of the regression pipeline (first few rows):
| additive_terms | additive_terms_lower | additive_terms_upper | anomalies | anomalies_severity | anomalies_type | anomaly_score | baseline | cluster | daily | daily_lower | daily_upper | is_anomaly | lowerBound | multiplicative_terms | multiplicative_terms_lower | multiplicative_terms_upper | predicted | timestamp | trend | trend_lower | trend_upper | upperBound | weekly | weekly_lower | weekly_upper | all-baseline |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 24842.31 | 24842.31 | 24842.31 | 0 | 18591059.0 | 16602.192 | 16602.192 | 16602.192 | No | 16411212.15 | 0.0 | 0.0 | 0.0 | 17674266.36 | 2022-02-19 12:00:00 | 17649424.05 | 17649424.052 | 17649424.052 | 18929811.82 | 8240.12 | 8240.117 | 8240.117 | 18591059.0 | ||||
| 67210.457 | 67210.457 | 67210.457 | 0 | 17199953.5 | 75488.112 | 75488.112 | 75488.112 | No | 16442403.49 | 0.0 | 0.0 | 0.0 | 17715151.22 | 2022-02-19 16:00:00 | 17647940.76 | 17647940.762 | 17647940.762 | 18929167.33 | -8277.65 | -8277.655 | -8277.655 | 17199953.5 | ||||
| 134117.35 | 134117.35 | 134117.35 | 0 | 17668196.5 | 150498.706 | 150498.706 | 150498.706 | No | 16532653.32 | 0.0 | 0.0 | 0.0 | 17780574.82 | 2022-02-19 20:00:00 | 17646457.47 | 17646457.473 | 17646457.473 | 18956964.78 | -16381.36 | -16381.356 | -16381.356 | 17668196.5 | ||||
| -318705.236 | -318705.236 | -318705.236 | 0 | 16852331.5 | -296692.927 | -296692.927 | -296692.927 | No | 16091106.07 | 0.0 | 0.0 | 0.0 | 17326268.95 | 2022-02-20 00:00:00 | 17644974.18 | 17644974.183 | 17644974.183 | 18501706.45 | -22012.31 | -22012.31 | -22012.31 | 16852331.5 |
Let us examine one row:
| Column | Value |
|---|---|
| additive_terms | 24842.31 |
| additive_terms_lower | 24842.31 |
| additive_terms_upper | 24842.31 |
| anomalies | |
| anomalies_severity | |
| anomalies_type | 0 |
| anomaly_score | |
| baseline | 18591059.0 |
| cluster | |
| daily | 16602.192 |
| daily_lower | 16602.192 |
| daily_upper | 16602.192 |
| is_anomaly | No |
| lowerBound | 16411212.15 |
| multiplicative_terms | 0.0 |
| multiplicative_terms_lower | 0.0 |
| multiplicative_terms_upper | 0.0 |
| predicted | 17674266.36 |
| timestamp | 2022-02-19 12:00:00 |
| trend | 17649424.05 |
| trend_lower | 17649424.052 |
| trend_upper | 17649424.052 |
| upperBound | 18929811.82 |
| weekly | 8240.12 |
| weekly_lower | 8240.117 |
| weekly_upper | 8240.117 |
| all-baseline | 18591059.0 |
Here are some of the columns the bot adds:
- timestamp: Historical and forecasted timestamps
- baseline: Actual historical data
- lowerBound: Lower uncertainty level
- upperBound: Upper uncertainty level
- anomalies: Any value out of uncertainty levels is an Anomaly
- predicted: Predicted values by the model
- trend: Trend of the time series
- daily: Daily seasonality if exists
- weekly: Weekly seasonality if exists
For the forecasted period, baseline will be null and will have forecasted values in predicted column
Let us visualize the above output in CloudFabrix Operational Intelligence & Analytics product for better understanding:
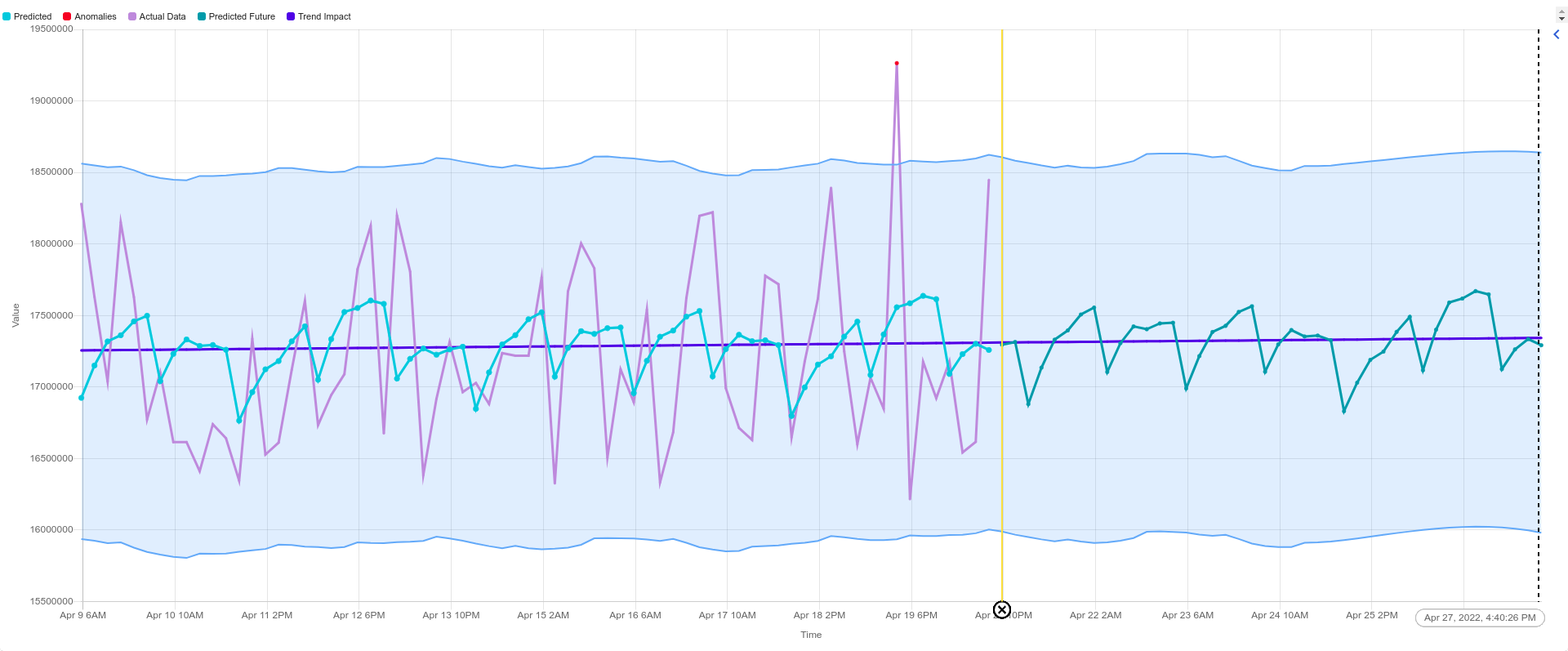
- Most of the time, memory usage is within the bounds and follows the trend line.
- The values out of the upper/lower bounds are considered as anomalies, here high memory usage is an anomaly that can be helpful to take preventive actions in the future.
- The forecasting period starts from vertical yellow line and we can interpret what might be the usage pattern in the future.
With the help of this Regression bot we can take very simple time series data and derive many insights with fast and accurate results.
4. Classification in RDA
Classification is a field of Supervised machine learning in which the algorithm learns how to predict a class label for a given set of input data. An easy to understand example is classifying emails as “spam” or “not spam.”
RDA Fabric's Classification bot @cfxml:classify-train leverages this technique and provides an efficient way for the users to train any Classification models for varied usecases and serve the model for live predictions in real time with help of @cfxml:classify-predict bot.
Lets us take an use case where we have raw incidents data and train a classification model to predict the priority of it. Then use the trained model to predict the priority based on input features like Summary, Project type, Issue Type and when ever new incident occurs the model helps user alert and take for necessary action if its in Blocker or High priority.
Here is how the sample training data looks like:
| Summary | Issue key | Issue id | Issue Type | Status | Project type | Priority | Resolution | Creator | Created | Updated |
|---|---|---|---|---|---|---|---|---|---|---|
| Rate plan is Showing as Non pooling in stead of Pooling | TEQTDM-478 | 322301 | Bug | Open | software | High | Canceled | AYajnas1@ACME123.org | 2020-01-29 14:51:00 | 2020-04-09 15:27:00 |
| JOD Upgrade: Getting 500 System Error in QLAB01 | TEQTDM-428 | 266678 | Feature | Postponed | software | High | Canceled | ARastog2@ACME123.org | 2019-12-30 13:07:00 | 2020-01-17 15:13:00 |
| CLONE - QLAB01_Sanity_Getting"Service call failed" After clicking on initiate while doing warranty exchange | TEQTDM-404 | 283021 | Bug | Closed | software | High | Canceled | AYajnas1@ACME123.org | 2020-01-09 13:12:00 | 2020-01-13 14:13:00 |
| PrepaidQE | QLAB06 | Rebellion Web | All Ship to Orders are failing in Web Channel. | TEQQEU2-7001 | 1406616 | Bug | Closed | software | Blocker | Done | PMakhij1@ACME123.org | 2021-01-19 17:22:00 | 2021-01-21 19:27:00 |
| PrepaidQE | Qlab02 | SAPCare | RebellionCare| Inflight Return | Getting remorse eligibility failure | TEQQEU2-6957 | 1399275 | Sub-task | New | software | Blocker | Done | NPrem@ACME123.org | 2021-01-15 22:35:00 | 2021-01-18 14:31:00 |
Let us load this file using @files:loadfile bot and use @cfxml:classify-train bot to train the classification model.
Here is how simple the classification training pipeline looks like
- Columns with natural language
- Class column
- Name of the model. This will be used in future predictions.
- Columns to be treated as categorical features
Playground
Here is how the Classification bot works:
- Input data to to the bot is multi class i.e it can have both text data like Summary, descriptions, comments aswell as any categorical data like Project Type, Issue type etc for training.
-
Let us elaborate on this and see what inputs the bot takes
a).
nlp_columns: What are the textual columns to be used for training which can be like Summary, descriptions, short_description, comments etc. Can be single or comma separated multiple columnsb).
category_columns: Name of the Categorical columns to be used. Categorical variables are usually represented as ‘strings’ or ‘categories’ and are finite in number for ex: Resolution codes, Issue types etc. Can be single or comma separated multiple columnsc).
target_column: The target variable of a dataset is the target feature which the model needs to be predicted. This is the output column that which the model wants to gain a deeper understanding and predict on new data. In this example its the priority that user wants to predict so that will be target column.d).
model_name: Name of the model for the trained data. -
First, it takes all the input data does pre_processing of data like : Stemming, Stop words removal, Lemmatisation, De-variabilization etc using its built-in NLP techniques.
- Next the bot takes the target column and checks for class imbalance (i.e if the training dataset has equal number of data points for each subsequent class), If found it rebalances dataset with its inbuilt techniques like Random under-sampling, Random over-sampling, SMOTE etc
- Then its does feature processing by projecting the data into high dimensional vectors using techniques like Tf-Idf, Word2Vec, Singular Value decomposition(SVD) etc for all text (nlp_columns) and transforms categorical and target columns using One-Hot encoding.
- The vectorised data is then fed into to its AutoML Classification engine where the model not just trains on a single algorithm instead uses multiple algorithms like SVM, SGD, Decision Trees, KNeighborsClassifier, RandomForests etc and many others, It runs on a grid search based technique to choose best parameters for each algorithm it uses and trains.
- The bot then evaluates each algorithm or model by maintaining track of validation metrics like Accuracy, Recall , Precision, F1 score etc
- It then chooses the best algorithm or model out of all and saves that model which is then ready for serving predictions in real time and also adds
predicted_labelto the dataset.
Once the training part is completed let us use @cfxml:classify-predict bot to predict the label for new data
Here is how the prediction pipeline looks like
Playground
Here is the sample output of new incidents with predicted label.
| Summary | Issue Type | Project type | Priority | Predicted Priority |
|---|---|---|---|---|
| QLAB01-trade quote API failing | Bug | software | Medium | Medium |
| PLAB|DASH|AddlineFlow| Get service Agreement is failing | Bug | software | High | High |
| Qlab03:- Order is not getting from SAP | Feature | software | Low | Low |
| PHP Protection SOC orders are failing with Activation failed | Bug | software | High | High |
| PrepaidQE | QLAB02 | ODA | For New Activation not received Welcome Email notification | Bug | software | High | Medium |
| Rebellion DIT | RAP | QLAB02 | OKTA Password reset is not successful | Feature | software | Low | Low |
To summarize, we took raw incidents data and trained classification model that can predict priority of an incident with the help of Summary, Project type, Issue Type as its input in real time.
Info
- Accuracy of the model depends on number of data used training, More the training/input data better accurate the predictions will be.