Guide to Application Dependency Mapping using RDA Bots
This guide has following sections:
- Application Dependency Mapping (ADM) concept in RDA Fabric
- Application Dependency Mapping (ADM) artifacts in RDA Fabric
- Creating Nodes & Edges pstream for an ADM topology stack in RDA Fabric
- Ingesting Nodes data for an ADM topology stack in RDA Fabric
- Ingesting Edges data for an ADM topology stack in RDA Fabric
- Generating an ADM topology stack in RDA Fabric
1. Application Dependency Mapping concept in RDA
Application Dependency Mappings (ADM) are essential for implementation of any Observability and AIOps projects. RDA provides necessary bots to automatically create & manage ADMs from any Cloud Native, Traditional Datacenter and Hybrid Cloud infrastructure.
RDA uses Stacks artifact as a way to refer to Application Dependency Mappings. Using Stacks, following can be accomplished:
- Automatically identify impacted entities when an alert is detected (Impact Analysis)
- Root cause identification
- Identify cohorts (Similar entities in a business application): Critical for doing metric & event correlation.
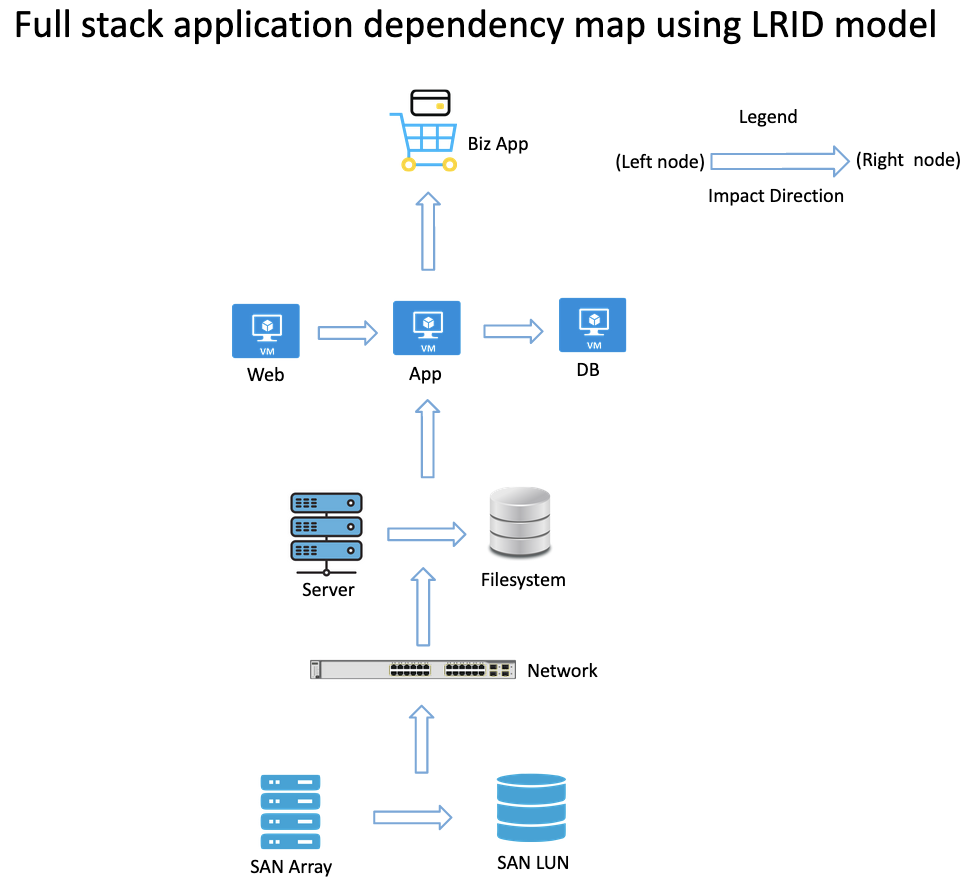
Application dependency mapping in RDA is established using LRID (left to right impact declaration) model. Within the LRID model, each object is identified as either impacting node (left) or impacted node (right).
The direction of the impact is from left node to right node, i.e. node(s) listed under Left node impacts the node(s) listed under Right node. Below table provides a sample example of LRID model. Relation Type defines how Left node is related to Right node.
| Left node |
Right node |
Relation Type |
| web01 |
bizapp_ecommerce |
member-of |
| app01 |
web01 |
depended-by |
| dbhost01 |
app01 |
depended-by |
| esxihost01 |
vm01 |
runs |
| datastore01 |
vm01 |
contains |
| lun01 |
datastore01 |
depended-by |
| storage_controller01 |
lun01 |
contains |
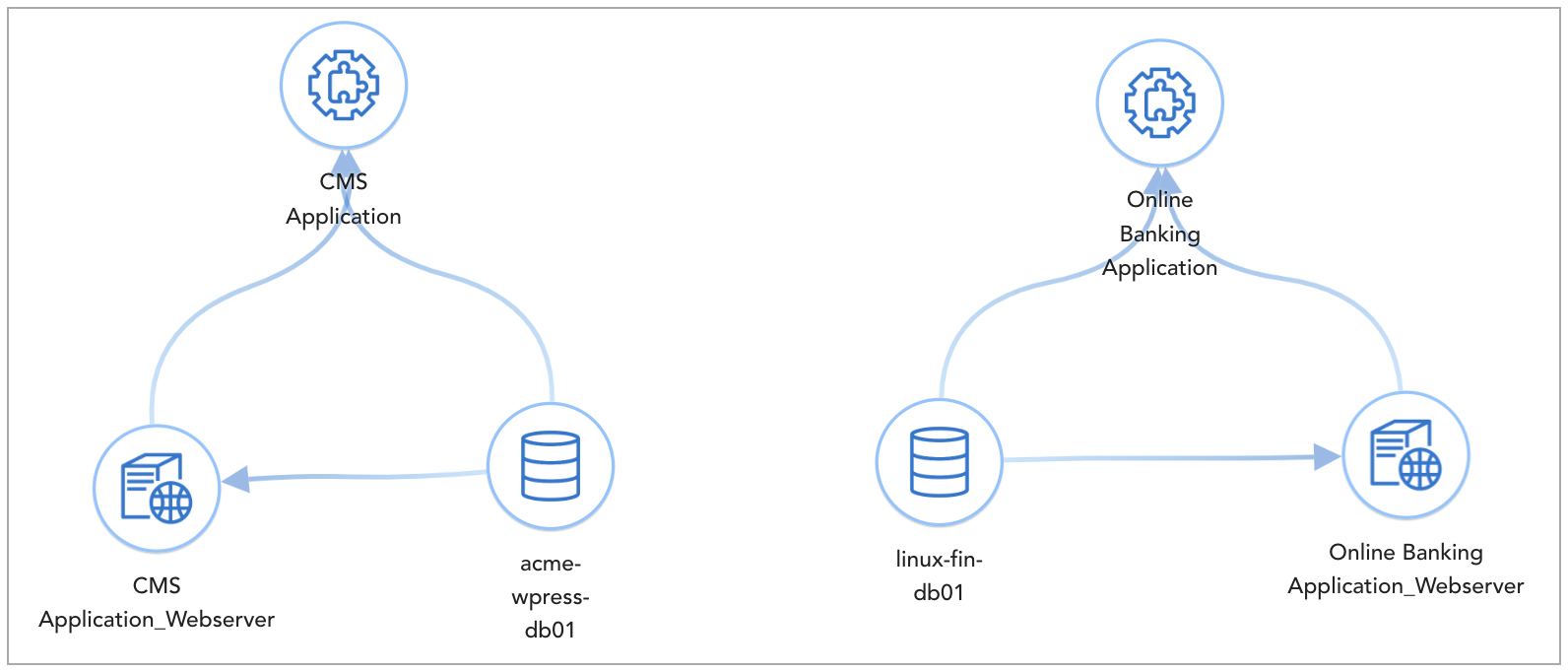
In the above example of application dependency mapping for a Business application called bizapp_ecommerce, it's underlying resource objects are defined as either Left node or Right node based on how they impact their neighbouring nodes and subsequently the upstream Business application.
What is a node ? - A node is an application or infrastructure component such as Web server, App server, Database, Virtual Machine, Switch, Server, Storage, Volume etc. which are connected to each other within the ADM stack.
2. Application Dependency Mapping artifacts in RDA
In order to generate an application dependency mapping (ADM) topology as depicted in the above picture, below are two types of datasets that need to be generated.
-
Nodes pstream: Nodes pstream consists of the properties of each node (such as application component, vm, server, switch, storage volume etc.) within the ADM topology. Additional to selecting each node's important properties such as name, ip address, uuid, mac address, version etc., below are the mandatory properties that need to be defined for each node:
- layer: Supported values are application, application component, virtualization, compute, network, storage
- node_id: Unique identifier of a node within the ADM topology
- node_type: Supported values are application, Webserver, Appserver, Database, Infraservice, Container, Process, Service, VM, OS, Host, Server, Switch, Router, Firewall, Load Balancer, LUN, Volume, Storage Pool, Storage Controller
- node_label: User friendly label name for each node within the ADM topology
-
Edges pstream: In edges pstream, each node is classified either as left node or right node using it's node_id that was defined in the above nodes pstream. Below are the properties that need to be defined within the edges pstream.
- left_id:
node_id of a node which is an impacting node
- right_id:
node_id of a node which is an impacted node
- left_label:
node_label of a node which is an impacting node
- right_label:
node_label of a node which is an impacted node
- left_node_type:
node_type of a node which is an impacting node
- right_node_type:
node_type of a node which is an impacted node
- relation_type: It defines how Left node is related to Right node. Below are some of the supported relation types, but not limited to
- runs
- runs-on
- connects
- connected-to
- member-of
- contains
- depended-by
3. Creating Nodes & Edges pstream for an ADM topology stack in RDA Fabric
Login into RDAF UI portal and go to Main Menu --> Configuration --> RDA Administration --> Persistent Streams
Add Nodes Pstream:
Click on Add button to create a new persistent stream
Select Datastore type and Enter persistent stream name.
Enter the persistent stream name as demo_topology_nodes_stream
Enter the below given configuration settings and click on Save button
{
"unique_keys": [
"node_id"
],
"default_values": {
"iconURL": "Not Available"
},
"search_case_insensitive": true,
"_settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"refresh_interval": "1s"
}
}
Add Edges Pstream:
Click on Add button to create a new persistent stream
Select Datastore type and Enter persistent stream name.
Enter the persistent stream name as demo_topology_edges_stream
Enter the below given configuration settings and click on Save button
{
"unique_keys": [
"left_id",
"right_id"
],
"search_case_insensitive": true,
"_settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"refresh_interval": "1s"
}
}
4. Ingesting Nodes data for an ADM topology stack in RDA Fabric
Login into RDAF UI portal and go to Main Menu --> Configuration --> RDA Administration --> Pipelines
Click on Add with Text button to create a new Topology Nodes Pipeline
Enter Pipeline Name as demo_topology_nodes_pipeline
Enter Version as 01
Enter the Pipeline Content (please see below)
Click on Save to save the pipeline
Click on demo_topology_nodes_pipeline settings (3 dot button) and click on Run button from the menu to execute the pipeline.
After submitting the pipeline job, Click on demo_topology_nodes_pipeline settings (3 dot button) and click on View Traces to see the progress of the pipeline.
Below one is a sample pipeline that ingests Nodes data into Nodes pstream using 2 tier application stack's sample data.
Info
When any of the node_id field or any other field which is going to be used as left_id or right_id and if it has has numeric value, please make sure to set it's data type as String using the below bot.
| --> @dm:to-type columns = 'node_id' & type = 'str'
|
| ## A Sample RDA pipeline to create ADM nodes and writes into Nodes pstream using the demo data
## The Demo data was generated from an APM tool which has the inventory data of one or more Business applications,
## Web/App services, Database services etc.
## Step-1:
## Load the business application dataset and define each business application node's properties.
## Start a new block in the pipeline
@c:new-block
## Load the demo business application dataset
--> @files:loadfile
filename = 'https://docs.fabrix.ai/data/datasets/demo_adm_biz_application_dataset.csv'
## Filter stale applications if there are any
--> *dm:filter app_name does not contain 'Petclinic'
## Add a new field called 'layer' and define it as 'Application'
--> @dm:eval
layer = "'Application'"
## Add a new field called 'node_type' and define it as 'Application'
--> @dm:eval
node_type = "'Application'"
## Clone the field 'app_name' to 'node_label'
--> @dm:map
from = 'app_name' & to = 'node_label'
## Clone the field 'app_id' to 'node_id'
--> @dm:map
from = 'app_id' & to = 'node_id'
## Set the app_id & node_id columns / field's data type as String
--> @dm:to-type columns = 'app_id,node_id' & type = 'str'
## Save the business application nodes data as a temporary in-memory dataset for further use within this pipeline
--> @dm:save
name = 'temp-biz_application_nodes'
## Write to Topology Nodes Pstream
--> @rn:write-stream name = 'demo_topology_nodes_stream'
## Step-2:
## Load the database services dataset and define each database service's node properties.
## Start a new block in the pipeline
--> @c:new-block
## Load the demo database service connections dataset
--> @files:loadfile
filename = 'https://docs.fabrix.ai/data/datasets/demo_adm_apps_to_db_conn_dataset.csv'
## Filter the records from 'exitPointType' field if it contains DB and JDBC values, remove any stale application connections and get the required fields
--> *dm:filter
exitPointType contains 'DB|JDBC' &
app_name does not contain 'Petclinic'
get HOST,app_name
## Remove the duplicate records using HOST field
--> @dm:dedup
columns = 'HOST'
## Save the database service connections data as a temporary in-memory dataset for further use within this pipeline
--> @dm:save
name = 'temp-db_backend_connections'
## Start a new block in the pipeline
--> @c:new-block
## Load the demo database servers dataset
--> @files:loadfile
filename = 'https://docs.fabrix.ai/data/datasets/demo_adm_db_server_nodes_dataset.csv'
## Filter the records that contain any stale DB services and get the required fields and rename them
--> *dm:filter name does not contain 'linux-petclinic-db01'
get host as 'db_dns_name',ipAddress as 'db_ip_address',name as 'db_hostname',id as 'db_id'
## Set the db_id column / field's data type as String
--> @dm:to-type columns = 'db_id' & type = 'str'
## Remove the duplicate records using db_ip_address field
--> @dm:dedup
columns = 'db_ip_address'
## Save the database servers data as a temporary in-memory dataset for further use within this pipeline
--> @dm:save
name = 'temp-db_servers'
## Start a new block in the pipeline
--> @c:new-block
## Reload the saved in-memory dataset 'temp-db_servers'
--> @dm:recall
name = 'temp-db_servers'
## Enrich the DB server dataset with DB service connections dataset and add the app_name field
--> @dm:enrich
dict = 'temp-db_backend_connections' &
src_key_cols = 'db_ip_address' &
dict_key_cols = 'HOST' &
enrich_cols = 'app_name'
## Remove/Exclude a field called HOST
--> @dm:selectcolumns
exclude = '^HOST$'
## Add a new field called 'layer' and define it as 'Application Component'
--> @dm:eval
layer = "'Application Component'"
## Add a new field called 'node_type' and define it as 'Database'
--> @dm:eval
node_type = "'Database'"
## Rename the field 'db_id' as 'node_id'
--> @dm:rename-columns
node_id = 'db_id'
## Derive database node's 'node_label' field from other fields 'db_hostname' & 'node_type'
--> @dm:map
from = 'db_hostname' &
to = 'node_label'
## Enrich the database node's dataset with business application's node_id
--> @dm:enrich
dict = 'temp-biz_application_nodes' &
src_key_cols = 'app_name' &
dict_key_cols = 'app_name' &
enrich_cols = 'app_id' &
enrich_cols_as = 'biz_app_id'
## Set the biz_app_id column / field's data type as String
--> @dm:to-type columns = 'biz_app_id' & type = 'str'
## Save the database nodes data as a temporary in-memory dataset for further use within this pipeline
--> @dm:save
name = 'temp-application_database_nodes'
## Write to Topology Nodes Pstream
--> @rn:write-stream name = 'demo_topology_nodes_stream'
## Step-3:
## Load the applications (web/app server) dataset and define each application service's node properties.
## Start a new block in the pipeline
--> @c:new-block
## Load the demo applications (web/app server) dataset
--> @files:loadfile
filename = 'https://docs.fabrix.ai/data/datasets/demo_adm_application_nodes_dataset.csv'
## Filter the records from 'ipAddress' field if it has a special character and a private IP address,
## remove any stale application services and get few required fields and rename them
--> *dm:filter
ipAddress does not contain ':' &
ipAddress does not contain '172.17.0.1' &
ipAddress does not contain '192.168.115' &
app_name does not contain 'Petclinic'
get name as 'app_hostname',
tierName as 'app_tier',
ipAddress as 'app_ip_address',
app_name as 'app_web_name',
id as 'app_web_id'
## Set the app_web_id column / field's data type as String
--> @dm:to-type columns = 'app_web_id' & type = 'str'
## Filter the application nodes that are Web server applications
--> *dm:filter
app_tier = 'Web'
## Add a new field called 'layer' and define it as 'Application Component'
--> @dm:eval
layer = "'Application Component'"
## Add a new field called 'node_type' and define it as 'Webserver'
--> @dm:eval
node_type = "'Webserver'"
## Rename the field 'app_id' as 'node_id'
--> @dm:rename-columns
node_id = 'app_web_id'
## Derive application service's 'node_label' field from other fields 'app_name' & 'node_type'
--> @dm:map
from = 'app_web_name,node_type' &
to = 'node_label' &
func = 'join' &
sep = '_'
## Enrich the application service node's dataset with business application's node_id
--> @dm:enrich
dict = 'temp-biz_application_nodes' &
src_key_cols = 'app_web_name' &
dict_key_cols = 'app_name' &
enrich_cols = 'app_id' &
enrich_cols_as = 'biz_app_id'
## Rename the app_name field
--> @dm:rename-columns biz_app_name = 'app_name'
## Set the biz_app_id column / field's data type as String
--> @dm:to-type columns = 'biz_app_id' & type = 'str'
## Remove/Exclude a field called app_name & app_web_name
--> @dm:selectcolumns
exclude = '^app_name$|^app_web_name$'
## Enrich the application service node's dataset with database service's node_id and DB Hostname
--> @dm:enrich
dict = 'temp-application_database_nodes' &
src_key_cols = 'biz_app_id' &
dict_key_cols = 'biz_app_id' &
enrich_cols = 'node_id,db_hostname' &
enrich_cols_as = 'db_node_id,db_hostname'
## Set the db_node_id column / field's data type as String
--> @dm:to-type columns = 'db_node_id' & type = 'str'
## Save the application web/app service nodes data as a temporary in-memory dataset for further use within this pipeline
--> @dm:save
name = 'temp-application_web_service_nodes'
## Write to Topology Nodes Pstream
--> @rn:write-stream name = 'demo_topology_nodes_stream'
## Step-4:
## Concatenate all of the nodes of Business application, Web/App services and Database services
## Start a new block in the pipeline
--> @c:new-block
## Use the below bot to combine all of node datasets that were created above
--> @dm:concat names = '^temp-biz_application_nodes$|^temp-application_database_nodes$|^temp-application_web_service_nodes$'
## Set the node_id column / field's data type as String
--> @dm:to-type columns = 'node_id' & type = 'str'
## Save the combined nodes as ADM nodes dataset
--> @dm:save name = 'rda_adm_biz_app_db_nodes_databaset'
|
5. Ingesting Edges data for an ADM topology stack in RDA Fabric
Login into RDAF UI portal and go to Main Menu --> Configuration --> RDA Administration --> Pipelines
Click on Add with Text button to create a new Topology Edges Pipeline
Enter Pipeline Name as demo_topology_edges_pipeline
Enter Version as 01
Enter the Pipeline Content (please see below)
Click on Save to save the pipeline
Click on demo_topology_edges_pipeline settings (3 dot button) and click on Run button from the menu to execute the pipeline.
After submitting the pipeline job, Click on demo_topology_edges_pipeline settings (3 dot button) and click on View Traces to see the progress of the pipeline.
Below one is a sample pipeline that ingests Nodes data into Nodes pstream using 2 tier application stack's sample data.
Below one is a sample pipeline that ingests Edges data into Edges pstream using 2 tier application stack's sample data.
| ## A Sample RDA pipeline to create ADM edges and writes into Edges pstream using the demo data
## The Demo data was generated from an APM tool which has the inventory data of one or more Business applications,
## Web/App services, Database services etc.
## 'Nodes pstream' that was generated will be used as input for populating the 'Edges pstream'
## Step-1:
## Load the 'Nodes dataset' and establish relationship between Web/App, DB and Biz application nodes
## Start a new block in the pipeline
--> @c:new-block
## Reload the 'Nodes dataset'
--> @dm:recall
name = 'rda_adm_biz_app_db_nodes_databaset'
## Define relationship between Web/App and Biz application nodes
## Here, Web/App node is going to be classified as impacting node (Left node) and
## Biz application node is going to be classified as impacted node (Right node)
## Filter the Web/App nodes
--> *dm:filter node_type = 'Webserver'
get node_id as 'left_id',
node_label as 'left_label',
node_type as 'left_node_type',
biz_app_id as 'right_id',
biz_app_name as 'right_label'
## Define right_node_type field
--> @dm:eval right_node_type = "'Application'"
## Add relationship type between Web/App and Biz application nodes
--> @dm:eval
relation_type = "'member-of'"
## Save it as in-memory dataset for further use with in the pipeline
--> @dm:save
name = 'temp-web_biz_app_relationship'
## Define relationship between Database and Biz application nodes
## Here, Database node is going to be classified as impacting node (Left node) and
## Biz application node is going to be classified as impacted node (Right node)
## Reload the 'Nodes dataset'
--> @dm:recall
name = 'rda_adm_biz_app_db_nodes_databaset'
## Filter the Database nodes
--> *dm:filter node_type = 'Database'
get node_id as 'left_id',
node_label as 'left_label',
node_type as 'left_node_type',
biz_app_id as 'right_id',
app_name as 'right_label'
## Define right_node_type field
--> @dm:eval right_node_type = "'Application'"
## Add relationship type between Database and Biz application nodes
--> @dm:eval
relation_type = "'member-of'"
## Save it as in-memory dataset for further use with in the pipeline
--> @dm:save
name = 'temp-db_biz_app_relationship'
## Define relationship between Web/App and Database nodes
## Here, Database node is going to be classified as impacting node (Left node) and
## Web/App node is going to be classified as impacted node (Right node)
## Reload the 'Nodes dataset'
--> @dm:recall
name = 'rda_adm_biz_app_db_nodes_databaset'
## Filter the Database nodes
--> *dm:filter node_type = 'Webserver'
get node_id as 'right_id',
node_label as 'right_label',
node_type as 'right_node_type',
db_node_id as 'left_id',
db_hostname as 'left_label'
## Define left_node_type field
--> @dm:eval left_node_type = "'Database'"
## Add relationship type between Database and Biz application nodes
--> @dm:eval
relation_type = "'connected-by'"
## Save it as in-memory dataset for further use with in the pipeline
--> @dm:save
name = 'temp-webapp_db_relationship'
## Step-2:
## Concatenate all of the Edge (relationships) datasets of Business application, Web/App services and Database services
## Start a new block in the pipeline
--> @c:new-block
## Use the below bot to combine all of edge (relationships) datasets that were created above
--> @dm:concat names = '^temp-web_biz_app_relationship$|^temp-db_biz_app_relationship$|^temp-webapp_db_relationship$'
## Set the lef_id,right_id columns / field's data type as String
--> @dm:to-type columns = 'left_id,right_id' & type = 'str'
## Remove any trailing whitespaces for left_id
--> @dm:map attr = 'left_id' & func = 'strip'
## Remove any trailing whitespaces for right_id
--> @dm:map attr = 'right_id' & func = 'strip'
## Filter out if Left Node and Right Nodes are same
--> *dm:filter left_id != right_id
## Filter out if Left Node's Label is empty
--> *dm:filter left_label is not empty
## Filter out if Right Node's Label is empty
--> *dm:filter right_label is not empty
## Remove Duplicate records of left_id & right_id together
--> @dm:dedup columns = 'left_id,right_id'
## Filter selective fields and write to Topology Edges Pstream
--> *dm:filter * get left_label,left_id,left_node_type,relation_type,right_id,right_label,right_node_type
## Write to Topology Edges Pstream
--> @rn:write-stream name = 'demo_topology_edges_stream'
|
5. Generating an ADM topology stack in RDA Fabric
Login into RDAF UI portal and go to Main Menu --> Configuration --> RDA Administration --> Stacks
Click on Add Stack button to create a new Topology Stack
Enter the Stack Name as as demo_app_topology
Enter the Description as Demo Application Topology
Select the Stack Type as Dynamic
Enter the below configuration settings for the stack using Nodes pstream and Edges pstream and Click on Save button.
{
"name": "demo_app_topology",
"description": "Demo Application Topology",
"saved_time": "2023-11-16T19:28:26.628904",
"is_dynamic": true,
"hierarchical": true,
"dynamic_nodes": {
"stream": "demo_topology_nodes_stream",
"query": "timestamp is after -90d",
"limit": 0,
"sorting": null
},
"dynamic_relationships": {
"stream": "demo_topology_edges_stream",
"query": "timestamp is after -90d",
"limit": 0,
"sorting": null
}
}
To see the final ADM topology stack, click on the demo_app_topology stack name which was created or click on the View Topology from the action buttons.